河北省沧州市东光县东光镇
河北省沧州市东光县东光镇
2026世界杯赔率与预测技术的深度融合
随着2026世界杯临近,围绕夺冠热门和比赛结果的讨论早早升温,而赔率不再只是简单反映市场情绪的数字,它正逐步成为各类预测技术的集成窗口。过去球迷更多依赖直觉和媒体观点,如今,算法模型、海量数据和实时信息流共同塑造着新一代世界杯赔率体系。对于关注足球与数据交汇点的人而言,2026世界杯赔率所展现的技术应用趋势,实际上折射出体育预测行业的整体升级方向。

数据驱动正在重塑世界杯赔率逻辑
在传统框架下,博彩公司制定赔率主要依靠历史战绩、专家经验和市场调研,属于典型的经验主义加定性分析模式。进入2026世界杯周期后,大规模数据采集与建模成为主流,从联赛表现、国家队集训情况到球员身体负荷,几乎一切可量化的信息都被纳入建模环节。机构会通过预期进球值xG、压迫强度PPDA、纵深跑动距离、阵型稳定度等指标构建多维度评分系统,再结合对抗强度和赛程密度,形成更为精细的初始赔率。
这种数据驱动趋势不只提升了赔率的精度,也改变了赔率的反馈速度。当某支球队在预选赛或热身赛中表现出高压逼抢效率显著提升的迹象时,模型会迅速调高其进攻评分,从而提前反映在2026世界杯相关盘口上。与以往依赖舆论发酵不同,现在是数据先行、市场跟随,赔率正变成一种动态的实力温度计。
机器学习模型成为赔率预测的技术核心
在应用层面,目前多家国际机构已将机器学习与深度学习模型引入世界杯赔率预测链路,其中常见的有梯度提升树、随机森林以及基于神经网络的序列模型。它们通过学习上届世界杯、洲际赛事以及各大联赛中数以万计比赛样本,提取隐含的胜负与进球模式。与经典的泊松回归或Elo评级相比,这类模型在处理非线性和复杂交互时更具优势,尤其能捕捉到战术风格与球员类型组合所产生的微妙效应。
例如,在模拟某支南美球队的2026世界杯小组赛出线概率时,模型不仅考虑球队在过去三届大赛中的战绩,还会引入其对阵高位逼抢球队时的表现、长途奔袭所带来的体能衰减曲线,甚至包括关键球员在高压比赛中的决策速度与失误率。通过数十万次蒙特卡洛模拟,模型形成的胜平负概率分布再被转化为赔率。对于外部用户来说,看到的是一组数字变化,但其背后是整个机器学习体系的实时演算。
实时情报与微观事件正在压缩赔率反应时间
2026世界杯赔率的另一个显著趋势是与实时信息流高度关联。社交媒体爬虫、训练场边线报、甚至航班与酒店信息都被纳入风险系统。当模型捕捉到关键球员缺席训练的图像或视频,再结合历史伤病记录做出受伤概率判断,赔率调整会比新闻报道提前数小时甚至更久。这样一种“情报前移”机制,使赔率变得前所未有的敏感。
在实战中,曾有欧洲杯预选赛作为预演案例:某队核心前锋在赛前两天被拍到单独在体能教练陪同下慢跑,图像识别系统发现其跑姿与之前受伤阶段的姿态高度相似,模型将此标记为复发风险升高,输出结果推高了对手胜率约2个百分点。尽管这一微调在赔率页面上只有细小浮动,但在大资金博弈中已经足以改变资金流向。这一案例说明,未来在2026世界杯期间,赔率调整将在更多未公开消息落地之前就先行一步。

复杂仿真场景推动更立体的盘口设计
除了传统的胜平负和总进球数,围绕2026世界杯的赔率设计也愈发多样化与场景化。依托复杂仿真系统,机构可以构建诸如首粒进球方式、特定球员在特定时间段进球、战术调整触发影响等精细市场。仿真引擎会将比赛划分为多个阶段,结合体能消耗模型和换人策略预测,模拟出不同战术情景下的事件发生概率。
举例来说,对一支擅长利用下半场反击的非洲球队,模型会将其在60分钟后的进球概率单独建模,从而衍生出“下半场进球数大于上半场”“80分钟后进球”等特殊盘口。对于关注2026世界杯赔率变化的用户,理解这些盘口的技术逻辑比简单看赔率数字更重要,因为它体现了机构对球队风格和比赛节奏的量化判断。
解释性与可视化提升预测技术的信任度

随着算法复杂度提升,如何让外界理解赔率背后的技术依据成为新课题。许多数据公司开始提供赔率预测可视化仪表盘,利用热力图、概率曲线和特征重要性排名等方式解释模型输出。例如,在分析某支欧洲劲旅的夺冠赔率时,系统会展示其防守稳定性、替补深度、关键球员健康指数对整体概率的贡献权重。用户可以清晰看到,可能是防守数据而非明星前锋的名气,在模型中扮演了更核心的角色。
这种带有解释性的展示,既提升了普通用户对2026世界杯赔率的理解门槛,也让专业投资者可以进行模型对模型的对比,将自身的预测系统与外部赔率进行交叉验证。当两者分歧较大时,往往意味着存在信息不对称或市场尚未完全消化的新变量,这会成为资本关注的重点区间。
监管与伦理为技术应用划定边界
技术深入后,围绕世界杯赔率的监管与伦理议题也愈发突出。一方面,高频算法交易与超快信息获取在赔率市场中的运用,容易造成普通用户在时间和信息上的天然劣势;另一方面,若模型将过多个体隐私数据纳入分析,又会触及数据合规的红线。部分地区监管机构已经开始要求预测模型在使用球员数据时进行匿名化处理,同时限制利用未经授权的训练内容或医疗记录。
在2026世界杯这一全球焦点事件中,如何在技术创新与公平环境之间取得平衡,将决定赔率生态的长期健康。业界正在探索使用差分隐私、联邦学习等技术手段,以保证在不直接暴露敏感数据的情况下完成预测建模。这些看似抽象的技术尝试,最终都将折射到一个具体指标上––赔率是否既精准又公允。
面向未来的应用趋势展望

从目前的发展轨迹来看,围绕2026世界杯赔率的技术应用会呈现几大趋势一是多源数据的进一步融合,包括可穿戴设备输出的体能指标、比赛中实时位置数据以及战术板数据;二是个体化预测的崛起,针对单一球员的表现赔率会更加丰富,模型也会更关注球员心理与决策风格;三是交互式预测平台的普及,用户可以在可视化界面中调整变量,实时查看不同设定下的比分与赔率变化,以此更直观地理解预测技术。
对于希望深度参与2026世界杯赔率市场的人来说,真正的差异化优势不再是信息早到几分钟,而是能否读懂赔率背后的技术逻辑––理解哪些变化源自数据模型的理性调整,哪些则是情绪驱动的短期波动。当赔率成为预测技术的综合载体时,谁能在技术理解与风险管理上占据主动,谁就有机会在这场全球性赛事的数字博弈中掌握节奏。

世界杯买球:揭秘菠菜公司的盈利模式

世界杯投注:如何提高你的投注胜率指南
2026世界杯下注:高风险下注如何避免亏损
世界杯竞猜平台:带你玩转互动竞猜体验升级
笔记2026世界杯直播的最佳策略
笔记2026世界杯直播的最佳策略

世界杯下注入口:选择高回报率的策略
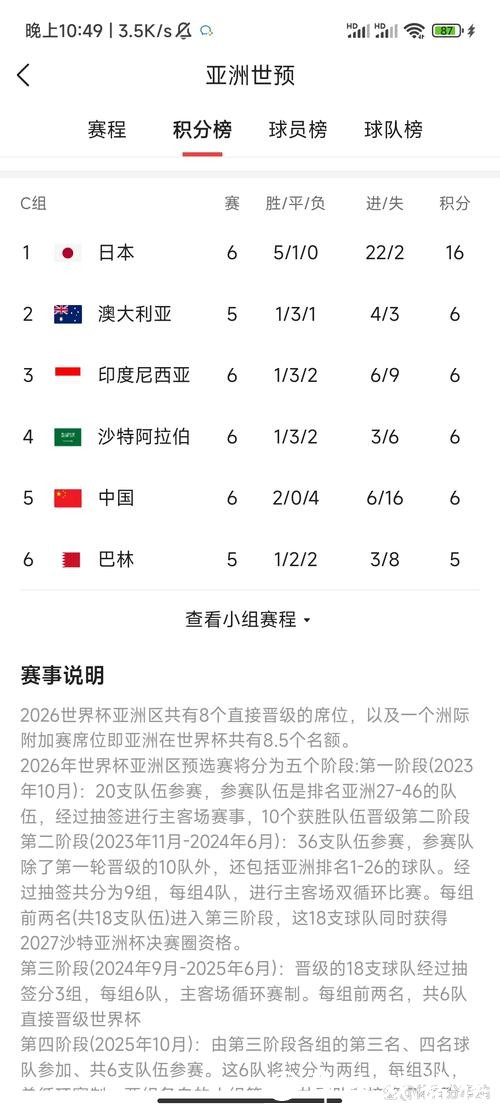
2026世界杯比分与积分榜实时统计
世界杯下注平台玩家互动社区推荐
2026世界杯竞猜:投注技巧助你精准押注